
HYPOTHESIS TESTING PART III LEARNING GOALS become able to - PowerPoint PPT Presentation
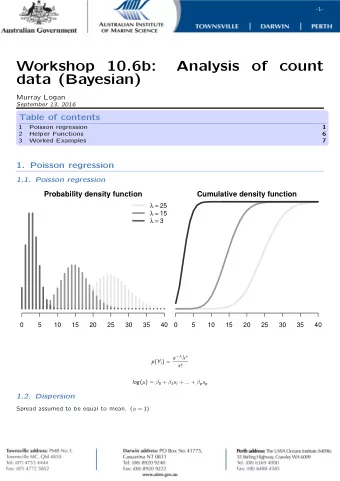
INTRODUCTION TO DATA ANALYSIS HYPOTHESIS TESTING PART III LEARNING GOALS become able to interpret & apply some statistical tests Pearsons -tests of independence 2 z -test one-sample t -test two-sample t -test
INTRODUCTION TO DATA ANALYSIS HYPOTHESIS TESTING PART III
LEARNING GOALS ▸ become able to interpret & apply some statistical tests ▸ Pearson’s -tests of independence χ 2 ▸ z -test ▸ one-sample t -test ▸ two-sample t -test ▸ one-way ANOVA ▸ understand differences and commonalities of different approaches to frequentist testing ▸ Fisher ▸ Neyman/Pearson ▸ modern hybrid NHST
P-VALUE p ( D obs ) = P ( T | H 0 ⪰ H 0, a t ( D obs ))
Pearson’s χ 2 -test goodness of fit
χ 2 PEARSON -TESTS ▸ tests for categorical data (with more than two categories) ▸ two flavors: ▸ test of goodness of fit ▸ test of independence ▸ sampling distribution is a -distribution χ 2
χ 2 -DISTRIBUTION ▸ standard normal random variables: X 1 , … X n ▸ derived RV: Y = X 2 1 + … + X 2 n ▸ it follows (by construction) that: y ∼ χ 2 - distribution( n )
PEARSON’S -TEST [GOODNESS OF FIT] χ 2 Is it conceivable that each category (= pair of music+subject choice) has been selected with the same flat probability of 0.25?
⃗ ⃗ ⃗ ⃗ FREQUENTIST MODEL FOR PEARSON’S -TEST [GOODNESS OF FIT] χ 2 n ∼ Multinomial( p p , N ) N k ( n i − np i ) 2 χ 2 = ∑ np i i =1 n Sampling distribution: χ 2 ∼ χ 2 - distribution( k − 1) χ 2
⃗ ⃗ PEARSON’S -TEST [GOODNESS OF FIT] χ 2 p N n χ 2 k ( n i − np i ) 2 χ 2 = ∑ np i i =1 χ 2 ∼ χ 2 - distribution( k − 1)
⃗ ⃗ PEARSON’S -TEST [GOODNESS OF FIT] χ 2 p N n χ 2 k ( n i − np i ) 2 χ 2 = ∑ np i i =1 χ 2 ∼ χ 2 - distribution( k − 1)
⃗ ⃗ PEARSON’S -TEST [GOODNESS OF FIT] χ 2 p N n χ 2 k ( n i − np i ) 2 χ 2 = ∑ np i i =1 χ 2 ∼ χ 2 - distribution( k − 1)
PEARSON’S -TEST [GOODNESS OF FIT] χ 2 How to interpret / report the result: What about the lecturer’s conjecture that (colorfully speaking) logic + metal = 🥱 ?
Pearson’s χ 2 -test independence
STOCHASTIC INDEPENDENCE ▸ events and are stochastically independent iff A B ▸ intuitively: learning one does not change beliefs about the other; ▸ formally: P ( A ∣ B ) = P ( A ) ▸ notice that entails that (see web-book) P ( A ∣ B ) = P ( A ) P ( B ∣ A ) = P ( B )
STOCHASTIC INDEPENDENCE
PEARSON’S -TEST [INDEPENDENCE] χ 2 Is it conceivable that the outcome in each cell is given by independent choices of row and column options? Hence: is the probability of a choice of cell the product of the probability of row- and column choices?
⃗ ⃗ ⃗ ⃗ ⃗ ⃗ ⃗ ⃗ ⃗ FREQUENTIST MODEL FOR PEARSON’S -TEST [INDEPENDENCE] χ 2 r c p = vec . of outer product r & c n ∼ Multinomial( p , N ) p N k ( n i − np i ) 2 χ 2 = ∑ np i i =1 n Sampling distribution: χ 2 ∼ χ 2 - distribution ( ( k r − 1) ⋅ ( k c − 1) ) χ 2
⃗ ⃗ ⃗ ⃗ FREQUENTIST MODEL FOR PEARSON’S -TEST [INDEPENDENCE] χ 2 r c p N n χ 2
⃗ ⃗ ⃗ ⃗ FREQUENTIST MODEL FOR PEARSON’S -TEST [INDEPENDENCE] χ 2 r c p N n k ( n i − np i ) 2 χ 2 = ∑ χ 2 np i i =1
⃗ ⃗ ⃗ ⃗ FREQUENTIST MODEL FOR PEARSON’S -TEST [INDEPENDENCE] χ 2 r c p N n χ 2
⃗ ⃗ ⃗ ⃗ FREQUENTIST MODEL FOR PEARSON’S -TEST [INDEPENDENCE] χ 2 r c p N n χ 2
FREQUENTIST MODEL FOR PEARSON’S -TEST [INDEPENDENCE] χ 2 How to interpret / report the result:
z- test
⃗ z SCENARIO FOR A -TEST [ONE-SAMPLE] ▸ metric variable with samples from normal distribution x ▸ unknown μ ▸ known [usually unrealistic!] σ Is it plausible to maintain that this data was generated by a normal distribution with mean 100 (if we assume that the standard deviation is known to be 15)?
z FREQUENTIST MODEL FOR A -TEST [ONE-SAMPLE] μ σ x i ∼ Normal( μ , σ ) x − μ z = ¯ σ / N x i Sampling distribution: z ∼ Normal(0,1) z
FREQUENTIST Z-TEST [APPLICATION] x i ∼ Normal( μ , σ ) x − μ z = ¯ σ / N z ∼ Normal(0,1)
FREQUENTIST Z-TEST [APPLICATION] x i ∼ Normal( μ , σ ) x − μ z = ¯ σ / N z ∼ Normal(0,1)
one-sample t- test
̂ ̂ ⃗ ̂ FREQUENTIST T-TEST MODEL [ONE-SAMPLE] x i ∼ Normal( μ , σ ) μ σ n 1 ∑ x ) 2 ( x i − μ σ = n − 1 i =1 x − μ 0 t = ¯ x i n σ / n Sampling distribution: t t ∼ Student - t( ν = n − 1)
t -DISTRIBUTION ▸ two random variables: x ∼ Normal(0,1) y ∼ χ 2 - distribution( n ) ▸ derived RV: X Z = Y / n ▸ it follows (by construction) that: z ∼ Student - t( ν = n − 1)
̂ ⃗ ̂ FREQUENTIST T-TEST [APPLICATION] x i ∼ Normal( μ , σ ) n 1 ∑ x ) 2 ( x i − μ σ = n − 1 i =1 x − μ 0 t = ¯ σ / n t ∼ Student - t( ν = n − 1)
⃗ ̂ ̂ FREQUENTIST T-TEST [APPLICATION] x i ∼ Normal( μ , σ ) n 1 ∑ x ) 2 ( x i − μ σ = n − 1 i =1 x − μ 0 t = ¯ σ / n t ∼ Student - t( ν = n − 1)
two-sample t- test (unpaired data, equal variance & unequal sample size)
COMPARING TWO GROUPS OF METRIC MEASURES Is it plausible to assume that the observed prices for conventional and organic avocados could have been generated by a single normal distribution?
̂ ̂ ̂ FREQUENTIST T-TEST MODEL [TWO-SAMPLE, UNPAIRED, EQUAL VARIANCE, UNEQUAL SAMPLE SIZES] x A i ∼ Normal( μ + δ , σ ) μ δ x B i ∼ Normal( μ , σ ) σ 2 σ 2 ( n A − 1) ̂ A + ( n B − 1) ̂ ( n B ) 1 + 1 B σ = σ n B n A + n B − 2 n A n A x A x B x B ) − δ ) ⋅ 1 t = ( (¯ i i x A − ¯ σ Sampling distribution: t t ∼ Student - t( ν = n A + n B − 2)
̂ ̂ TWO-SAMPLE T-TEST EXAMPLE x A i ∼ Normal( μ + δ , σ ) x B i ∼ Normal( μ , σ ) σ 2 σ 2 ( n A − 1) ̂ A + ( n B − 1) ̂ ( n B ) 1 + 1 B σ = n A + n B − 2 n A x B ) − δ ) ⋅ 1 t = ( (¯ x A − ¯ σ t ∼ Student - t( ν = n A + n B − 2)
̂ ̂ TWO-SAMPLE T-TEST EXAMPLE x A i ∼ Normal( μ + δ , σ ) x B i ∼ Normal( μ , σ ) σ 2 σ 2 ( n A − 1) ̂ A + ( n B − 1) ̂ ( n B ) 1 + 1 B σ = n A + n B − 2 n A x B ) − δ ) ⋅ 1 t = ( (¯ x A − ¯ σ t ∼ Student - t( ν = n A + n B − 2)
one-way ANOVA
COMPARING K ≥ 2 GROUPS OF METRIC MEASURES Is it plausible to assume that these measures stem from the same normal distribution?
t WHY NOT -TESTS? ▸ we could run -tests between t different groups ▸ chance of error rises with α each comparison ▸ common corrections apply ▸ gets tedious with large k
̂ ̂ ̂ ̂ FREQUENTIST MODEL FOR ANOVA [ONE-WAY] σ between x ij ∼ Normal( μ , σ ) F = σ within μ σ ∑ k j =1 ∑ n j x j ) 2 i =1 ( x ij − ¯ σ within = ∑ k i =1 ( n i − 1) x ij ∑ k x ) 2 x j − ¯ j =1 n j (¯ ¯ σ between = k − 1 Sampling distribution: F ∼ F - distribution ( k − 1, F ( n i − 1) ) k ∑ i =1
F-STATISTIC EXAMPLES
-DISTRIBUTION F ▸ two -distributed random variables: χ 2 x ∼ χ 2 - distribution( m ) y ∼ χ 2 - distribution( n ) ▸ derived RV: Z = X / m Y / n ▸ it follows (by construction) that: z ∼ F - distribution( m , n )
EXAMPLE
varieties of frequentist testing
THREE VARIETIES OF FREQUENTIST TESTING FISHER NEYMAN/PEARSON HYBRID NHST* explicit & serious X X ✓ alternative H a when to set-up after data before data after data statistical model collection collection collection goal of statistical quantify evidence decide action: decide action: analysis against H 0 adopt H 0 or H a adopt H 0 or ¬H 0 X X ✓ power calculation * this is a worst-case portrait of modern NHST ; this is not how it should be done
NEYMAN/PEARSON APPROACH [INFORMAL GIST] ▸ procedure in N/P approach: ▸ fix H 0 and H a (based on prior research) ▸ determine desired α - and β -error level ▸ calculate sample size N necessary for β given α ▸ run the experiment ▸ determine significance based on α -level ▸ make a dichotomous decision: ▸ accept H a if test is significant ▸ accept H 0 otherwise
LONG-TERM ERROR CONTROL IN NEYMAN/PEARSON APPROACH [more data = tighter curves!! = lower β ] [sampling distribution of mean under H 0 ] [sampling distribution of mean under H a ] [ β error = accept H 0 when H a is true] [ α error = accept H a when H 0 is true] [null-hypothesis] [alternative hypothesis]
EXAMPLES FROM TEXTBOOKS neither textbook talks about fixing Ha and/or calculating power of a test
THREE VARIETIES OF FREQUENTIST TESTING FISHER NEYMAN/PEARSON HYBRID NHST* explicit & serious X X ✓ alternative H a when to set-up after data before data after data statistical model collection collection collection goal of statistical quantify evidence decide action: decide action: analysis against H 0 adopt H 0 or H a adopt H 0 or ¬H 0 X X ✓ power calculation * this is a worst-case portrait of modern NHST ; this is not how it should be done
Recommend






















![Higgs Measurements at a Muon Collider Higgs Factory [Preliminary] Alexander Conway, UChicago](https://c.sambuz.com/1004844/higgs-measurements-at-a-muon-collider-higgs-factory-s.webp)
More recommend
Explore More Topics
Stay informed with curated content and fresh updates.