Disk Drives and Geometry File Systems: Performance & Robustness - PDF document
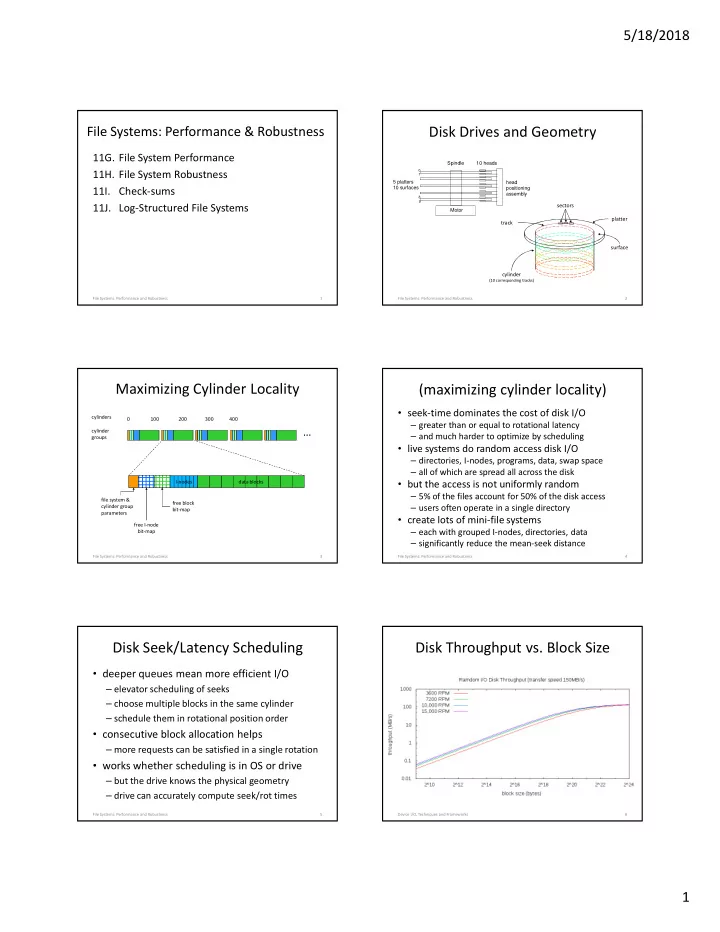
5/18/2018 Disk Drives and Geometry File Systems: Performance & Robustness 11G. File System Performance Spindle 10 heads 11H. File System Robustness 0 1 5 platters head 10 surfaces 11I. Check-sums positioning assembly 8 9 11J.
5/18/2018 Disk Drives and Geometry File Systems: Performance & Robustness 11G. File System Performance Spindle 10 heads 11H. File System Robustness 0 1 5 platters head 10 surfaces 11I. Check-sums positioning assembly 8 9 11J. Log-Structured File Systems sectors Motor platter track surface cylinder (10 corresponding tracks) File Systems: Performance and Robustness 1 File Systems: Performance and Robustness 2 Maximizing Cylinder Locality (maximizing cylinder locality) • seek-time dominates the cost of disk I/O cylinders 0 100 200 300 400 – greater than or equal to rotational latency … cylinder – and much harder to optimize by scheduling groups • live systems do random access disk I/O – directories, I-nodes, programs, data, swap space – all of which are spread all across the disk I-nodes data blocks • but the access is not uniformly random – 5% of the files account for 50% of the disk access file system & free block cylinder group – users often operate in a single directory bit-map parameters • create lots of mini-file systems free I-node – each with grouped I-nodes, directories, data bit-map – significantly reduce the mean-seek distance File Systems: Performance and Robustness 3 File Systems: Performance and Robustness 4 Disk Seek/Latency Scheduling Disk Throughput vs. Block Size • deeper queues mean more efficient I/O – elevator scheduling of seeks – choose multiple blocks in the same cylinder – schedule them in rotational position order • consecutive block allocation helps – more requests can be satisfied in a single rotation • works whether scheduling is in OS or drive – but the drive knows the physical geometry – drive can accurately compute seek/rot times File Systems: Performance and Robustness 5 Device I/O, Techniques and Frameworks 6 1
5/18/2018 Allocation/Transfer Size Block Size vs. Internal Fragmentation • per operation overheads are high • Large blocks are a performance win – DMA startup, seek, rotation, interrupt service – fewer next-block lookup operations – fewer, larger I/O operations • larger transfer units more efficient • Internal fragmentation rises w/block sizes – amortize fixed per-op costs over more bytes/op – multi-megabyte transfers are very good – mean loss = block size / (2 * mean file size) • this requires space allocation units • Can we get the best of both worlds? – allocate space to files in much larger chunks – most blocks are very large – large fixed size chunks -> internal fragmentation – the last block is relatively small – therefore we need variable partition allocation File Systems: Performance and Robustness 7 File Systems: Performance and Robustness 8 Fragment Blocks I/O Efficient Disk Allocation • allocate space in large, contiguous extents block 1000 – few seeks, large DMA transfers I-node 301 block 1020 • variable partition disk allocation is difficult block 1001 I=250, len=175 I=301, len=400 1000 – many file are allocated for a very long time 1001 I=420, len=80 – space utilization tends to be high (60-90%) last fragment I 250 1020 – special fixed-size free-lists don’t work as well last fragment I 301 • external fragmentation eventually wins last fragment I 420 – new files get smaller chunks, farther apart – file system performance degrades with age File Systems: Performance and Robustness 9 File Systems: Performance and Robustness 10 Read Caching Read-Ahead • disk I/O takes a very long time • Request blocks before they are requested – deep queues, large transfers improve efficiency – store them in cache until later – they do not make it significantly faster – reduces wait time, may improve disk I/O • we must eliminate much of our disk I/O • When does it make sense? – maintain an in-memory cache – when client specifically requests sequential access – depend on locality, reuse of the same blocks – when client seems to be reading sequentially – read-ahead (more data than requested) into cache • What are the risks? – check cache before scheduling I/O – may waste disk access time reading unwanted blocks • all writes must go through the cache – may waste buffer space on unneeded blocks – ensure it is up-to-date File Systems: Performance and Robustness 11 2
5/18/2018 Performance Gain vs. Cache Size Special Purpose Caches performance • often block caching makes sense – files that are regularly processed Special Purpose Cache – indirect blocks that are regularly referenced • consider I-nodes (32 per 4K block) – only recently used I-nodes likely to be re-used • consider directory entries (256 per 4K block) General Block Cache – 1% of entries account for 99% of access • perhaps we should cache entire paths cache size (bytes) File Systems: Performance and Robustness 13 File Systems: Performance and Robustness 14 Special Caches – doing the math When can we out-smart LRU? • consider the hits per byte per second ratio • it is hard to guess what programs will need – e.g. 2 hits/4K block (.0005 hits/byte) • sometimes we know what we won’t re-read – e.g. 1 hits/32 byte dcache entry (.03 hits/byte) – load module/DLL read into a shared segment • consider the savings from extra hits – an audio/video frame that was just played – e.g. 50 block reads/second * 1.5ms/read = 75ms – a file that was just deleted or overwritten • consider the cost of the extra cache lookups – a diagnostic log file – e.g. 1000 lookup/s * 50ns per lookup = 50us • dropping these files from the cache is a win • consider the cost of keeping cache up to date – allows a longer life to the data that remains there – e.g. 100 upd/s * 150ns per upd = 15us • net benefit: 75ms – 65us = 74.935ms/s File Systems: Performance and Robustness 15 File Systems: Performance and Robustness 16 Write-Back Cache Persistence vs Consistency • Posix Read-after-Write Consistency • writes go into a write-back cache – any read will see all prior writes – they will be flushed out to disk later – even if it is not the same open file instance • aggregate small writes into large writes • Flush-on-Close Persistence – if application does less than full block writes – write(2) is not persistent until close(2) or fsync(2) • eliminate moot writes – think of these as commit operations – if application subsequently rewrites same data – close(2) might take a moderately long time – if application subsequently deletes the file • This is a compromise … • accumulate large batches of writes – strong consistency for multi-process applications – a deeper queue to enable better disk scheduling – enhanced performance from write-back cache File Systems: Performance and Robustness 17 File Systems: Performance and Robustness 18 3
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.