
Bottom Up Parsing Also known as Shift-Reduce parsing More powerful - PDF document
9/26/2012 Bottom Up Parsing Also known as Shift-Reduce parsing More powerful than top down Dont need left factored grammars Can handle left recursion Bottom Up Parsing Attempt to construct parse tree from an input string
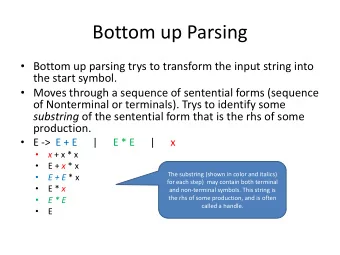
9/26/2012 Bottom Up Parsing Also known as Shift-Reduce parsing More powerful than top down • Don’t need left factored grammars • Can handle left recursion Bottom Up Parsing Attempt to construct parse tree from an input string • beginning at leaves and working to top • Process of reducing strings to a non terminal – shift-reduce • Uses parse stack • Contains symbols already parsed • Shift until match RHS of production • Reduce to non-terminal on LHS • Eventually reduce to start symbol Shift and Reduce Sentential Form A sentential form is a member of (T N)* that can be derived in a finite Shift: number of steps from the start symbol S. • Move the first input token to the top of the stack. A sentential form that contains no nonterminal symbols (i.e., is a member of T*) is Reduce: called a sentence . • Choose a grammar rule X → ɑ β γ • pop γ β ɑ from the top of the stack • push X onto the stack. Stack is initially empty and the parser is at the beginning of the input. Shifting $ is accepts . Handle Parse Tree S Intuition : reduce only if it leads to the start symbol S b M b M ( L M a Handle has to b M b L M a ) • match RHS of production and • lead to rightmost derivation, if reduced to LHS of some rule L ) ( L Definition: Considering string: M a ) Let w be a sentential form where: • b ( a a ) b is an arbitrary string of symbols a X is a production w is a string of terminals S b M b b ( L b b ( M a ) b b ( a a ) b Then at is a handle of w if S Xw w by a rightmost derivation Try to find handles and then reduce from sentential form via rightmost derivation b ( a a ) b b ( M a ) b b ( L b b M b S Handles formalize the intuition (reduce to X ), but doesn’t say how to • find the handle 1
9/26/2012 Bottom Up Parsing Issues We need to locate the handle in the right sentential Grammar Sentential form Handle Products E E + E form and then decide what production to reduce it to – E id id 1 + id 2 * id 3 id 1 which of the RHS of our grammar. E E * E E id E + id 2 * id 3 id 2 E ( E ) E + E * id 3 id 3 E id Notice in right-most derivation, where right sentential E id S 1 form is: E + E * E E*E E E*E E + E E+E E E+E b M b 2 E ( L 3 Use • to indicate where we are in string: Parsing never has to guess about the middle of the string. The right side always contains terminals. M a ) 4 id 1 • + id 2 * id 3 E • + id 2 * id 3 E + • id 2 * id 3 E + E • * id 3 E + E * id 3 • E + E * E • Thus, we can discover the rightmost derivation in a E + E • E reverse: 4 3 2 1 Bottom Up Parsing Viable Prefix Definition: is a viable prefix if Consider our usual grammar and the problem of when to reduce: E T + E | T • There is a w where w is a right sentential form T int * T | int | ( E ) • • w is a configuration of a shift-reduced parser b ( a • a ) b b ( M • a ) b b ( L • b b M • b S • For the string: int * int + int E Alternatively, a prefix of a rightmost derived sentential form is viable if it does not Sentential form Production extend the right end of the handle. T int T + E int * int + int T int * T int * T + int A prefix is viable because it can be extended by adding terminals to form a valid T int T + int int * T T (rightmost derived) sentential form E T T + T E T + E T + E int int As long as the parser has viable prefixes on the stack, no parsing error has been detected. E Parser Structure Parse S b M b Stack Input Action … Input Tokens: $ M ( L $ b ( a a ) b $ shift M a Read head $ b ( a a ) b $ shift L M a ) $ b ( a a ) b $ shift Top Output L ) Parser Driver Syntax $ b ( a a ) b $ reduce Stack $ b ( M a ) b $ shift String: Parse table b ( a a ) b $ $ b ( M a ) b $ shift $ b ( M a ) b $ reduce $ $ b ( L b $ reduce $ b M b $ shift Operations $ b M b $ reduce 1. Shift – shift input symbol onto the stack $ Z $ accept 2. Reduce – RHS of a non-terminal handle is at the top of the stack. Decide which non-terminal to reduce it to 3. Accept – success 4. Error 2
9/26/2012 Ambiguous Grammars Ambiguity Conflicts arise with ambiguous grammars In the first step shown, we can either shift or reduce by E E * E • Ambiguous grammars generate conflicts but so do other types of grammars • Choice because of precedence of + and * Example: • Same problem with association of * and + • Consider the ambiguous grammar E E * E | E + E | ( E ) | int We can always rewrite ambiguous grammars of this sort to encode precedence and association in the grammar • Sometimes this results in convoluted grammars. Sentential form Actions Sentential form Actions • The tools we will use have other means to encode precedence and int * int + int shift int * int + int shift association … … … … E * E • + int reduce E E * E E * E • + int shift We must get rid of conflicts ! E • + int shift E * E + • int shift • Know what a handle is but not clear how to detect it reduce E int E + • int shift E * E + int • reduce E int reduce E E + E E + int • E * E + E • reduce E E + E reduce E E * E E + E • E * E • E • E • Properties about Bottom Up Parsing LR Parsers Handles always appear at the top of the stack LR family of parsers • Never in middle of stack • LR(k) • Justifies use of stack in shift–reduce parsing • L – left to right • R – rightmost derivation in reverse General shift–reduce strategy • k elements of look ahead • If there is no handle on the stack, shift • If there is a handle, reduce to the non-terminal Attractive • LR(k) is powerful – virtually all language constructs Conflicts • Efficient • If it is legal to either shift or reduce then there is a shift-reduce conflict . • LL(k) LR(k) • If it is legal to reduce by two or more productions, then there is a • LR parsers can detect an error as soon as it is possible to do so reduce-reduce conflict. • Automatic technique to generate – YACC, Bison, Java CUP LR and LL Parsers Types of LR Parsers LR parser, each reduction needed for parse is detected on the basic of SLR – simple LR • Left context • Easiest to implement • Reducible phrase • Not as powerful • k terminals of look ahead Canonical LR LL parser • Most powerful • Left context • Expensive to implement • First k symbols of what right hand side derive (combined phrase and what is to right of phrase) LALR • Look ahead LR • In between the 2 previous ones in power and overhead Overall parsing algorithm is the same – table is different 3
9/26/2012 LR Parser Actions LR Parser Actions How does the LR parser know when to shift and when to reduce? Shift ( n ): • Advance input one token; push n on stack. By using a DFA! Reduce ( k ): The edges of the DFA are labeled by the symbols (terminals and non-terminals) • Pop stack as many times as the number of symbols on the right-hand that can appear on the stack. side of rule k • Let X be the left-hand-side symbol of rule k Five kinds of actions: • In the state now on top of stack, look up X to get “goto n ” Shift into state n ; • Push n on top of stack. 1. s n 2. g n Goto state n ; 3. r k Reduce by rule k ; Accept : Accept; • Stop parsing, report success . 4. a Error : 5. Error • Stop parsing, report failure . LR Parsers Notion of an LR(0) item Can tell handle by looking at stack top: An item is a production with a distinguished position on the right hand side. This position indicates how much of the production already seen. • (grammar symbol, state) and k input symbols index our FSA table • In practice, k<=1 Example: S a B S is a production How to construct LR parse table from grammar: 1. First construct SLR parser Items for the production: 2. LR and LALR are augmented basic SLR techniques S • a B S 3. 2 phases to construct table: S a • B S I. Build deterministic finite state automation to go from state to state S a B • S II. Build table from DFA S a B S • Each state – how do we know from grammar where we are in the parse. Production already seen. Basic idea : Construct a DFA that recognizes the viable prefixes group items into sets Construction of LR(0) items LR(0) States Create augmented grammar G’ Start with our usual grammar: G: S | 1.) E → T + E S’ S G’: 2.) T → int * T S | 3.) T → ( E ) What else is needed: Add a special start symbol, S, that goes to our original start symbol and $: • A c • d E 0.) S → E $ • Indicate a new state by consuming symbol d: need goto function • A c d • E The LR(0) start state will be the set of LR(0) items: • What are all possible things to see – all possible derivations from E? Add strings derivable from E – closure function S → • E $ • A c d E • – reduce to A and goto another state E → • T + E Compute functions closure and goto will be used to determine the action and T → • int * T goto parts of the parsing table T → • ( E ) • closure – essentially defines what is expected • goto – moves from one state to another by consuming symbol 4
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.