a shallow survey of deep learning Applications, Models, Algorithms and Theory (?) Chiyuan Zhang April 22, 2015 CSAIL, Poggio Lab
the state of the art
the state of the art Deep learning is achieving the state of the art performance in many standard prediction tasks. ∙ Computer vision: image classification, image summarization, etc. ∙ Speech recognition: acoustic modeling, language modeling, etc. ∙ Natural language processing: language modeling, word embedding, etc. ∙ Reenforcement learning: non-linear Q -function, etc. 2 ∙ . . .
the state of the art Imagenet Large Scale Visual Recognition Challenge (ILSVRC) 1 1000 categories, 1.2 million images, classification, localization and detection. 1 http://image-net.org/challenges/LSVRC/ 3
the state of the art LSVRC on Imagenet, deep learning from 2012 2 , surpassing “human Visual Recognition Challenge. arXiv:1409.0575 [cs.CV]. performance” this year. 4 30 22.5 15 7.5 0 2010 2011 2012 2013 2014 Human ArXiv 2015 Top-5 error 2 Olga Russakovsky, . . . , Andrej Karpathy and Li Fei-Fei et.al. ImageNet Large Scale
the state of the art Human-Level Performance ∙ Difficult for human because of fine-grained visual categories. ∙ Human and computer make different kinds of errors 3 . ∙ Try it out: http://cs.stanford.edu/people/karpathy/ilsvrc/ 3 http://karpathy.github.io/2014/09/02/ what-i-learned-from-competing-against-a-convnet-on-imagenet/ 5
the state of the art 4 Christian Szegedy, et. al. Going Deeper with Convolutions. arXiv:1409.4842 [cs.CV]. 6 softmax2 SoftmaxActivation FC AveragePool layers, ∼ 7 million parameters. 7x7+1(V) DepthConcat Conv Conv Conv Conv 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) Conv Conv MaxPool 1x1+1(S) 1x1+1(S) 3x3+1(S) DepthConcat Conv Conv Conv Conv softmax1 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) Conv Conv MaxPool SoftmaxActivation 1x1+1(S) 1x1+1(S) 3x3+1(S) MaxPool FC 3x3+2(S) DepthConcat FC Conv Conv Conv Conv Conv 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) 1x1+1(S) Conv Conv MaxPool AveragePool 1x1+1(S) 1x1+1(S) 3x3+1(S) 5x5+3(V) DepthConcat Conv Conv Conv Conv 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) Conv Conv MaxPool 1x1+1(S) 1x1+1(S) 3x3+1(S) DepthConcat softmax0 Conv Conv Conv Conv SoftmaxActivation 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) Conv Conv MaxPool FC 1x1+1(S) 1x1+1(S) 3x3+1(S) DepthConcat FC Conv Conv Conv Conv Conv 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) 1x1+1(S) Conv Conv MaxPool AveragePool 1x1+1(S) 1x1+1(S) 3x3+1(S) 5x5+3(V) DepthConcat Conv Conv Conv Conv 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) Conv Conv MaxPool The model called “Inception” (GoogLeNet) 4 that won ILSVRC 2014. 27 1x1+1(S) 1x1+1(S) 3x3+1(S) MaxPool 3x3+2(S) DepthConcat Conv Conv Conv Conv 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) Conv Conv MaxPool 1x1+1(S) 1x1+1(S) 3x3+1(S) DepthConcat Conv Conv Conv Conv 1x1+1(S) 3x3+1(S) 5x5+1(S) 1x1+1(S) Conv Conv MaxPool 1x1+1(S) 1x1+1(S) 3x3+1(S) MaxPool 3x3+2(S) LocalRespNorm Conv 3x3+1(S) Conv 1x1+1(V) LocalRespNorm MaxPool 3x3+2(S) Conv 7x7+2(S) input
the state of the art 5 Rob Fergus et. al. Intriguing properties of neural networks. arXiv:1312.6199 [cs.CV] 6 Ian J. Goodfellow et. al. Explaining and Harnessing Adversarial Examples. arXiv:1412.6572 [stat.ML] 7 (Deep) neural networks could be easily fooled 5 , 6 .
the state of the art image source: Li Deng and Dong Yu. Deep Learning – Methods and Applications . Deep learning in speech recognition. Deployed in production. 7 Andrew Ng et. al. Deep Speech: Scaling up end-to-end speech recognition. arXiv:1412.5567 [cs.CL] 8 e.g. Baidu Deep Speech 7 , RNN trained on 100,000 hours of data (100 , 000 / 365 / 5 ≈ 55).
the state of the art Image captioning: parse image, generate text (CNN + RNN). 9
the state of the art Image captioning (not quite there yet) for Generating Image Descriptions. http://cs.stanford.edu/people/karpathy/deepimagesent/ ∙ Demo page: http://cs.stanford.edu/people/karpathy/ deepimagesent/generationdemo/ ∙ Toronto group’s image to text demo: http://www.cs.toronto. edu/~nitish/nips2014demo/index.html 10 ∙ Andrej Karpathy and Li Fei-Fei. Deep Visual-Semantic Alignments
the state of the art Reenforcement learning to play video games 8 8 Google Deep Mind. Human-level control through deep reinforcement learning. Nature, Feb. 2015. 11
the state of the art close to an AI. Attracted a lot of media 12 games sounds more attention because learning to play video Video Pinball Boxing Breakout Star Gunner Robotank Atlantis Crazy Climber Gopher Demon Attack Name This Game Krull Assault Road Runner Kangaroo James Bond Tennis Pong Space Invaders Beam Rider Tutankham Kung-Fu Master Freeway Time Pilot Enduro Fishing Derby Up and Down Ice Hockey Q*bert At human-level or above H.E.R.O. Asterix Below human-level Battle Zone Wizard of Wor Chopper Command Centipede Bank Heist River Raid Zaxxon Amidar Alien Venture Seaquest Double Dunk Bowling Ms. Pac-Man Asteroids Frostbite Gravitar DQN Private Eye Best linear learner Montezuma's Revenge 0 100 200 300 400 500 600 1,000 4,500%
models
basic setting collection of images), learn something about p x . Typically, the goal is to find some representation that captures the main property of the data distribution that is compact, or sparse, or “high-level”, etc. ∙ Clustering : K-means clustering, Gaussian Mixture Models, etc. ∙ Dictionary Learning : Principle Component Analysis (Singular Value Decomposition), Sparse Coding, etc. Typical goal is to approximate the regression function 14 ∙ Unsupervised Learning: Given signals x 1 , . . . , x N ∈ X (e.g. a ∙ Supervised Learning: Given i.i.d. samples { ( x 1 , y 1 ) , . . . , ( x N , y N ) } (e.g. image-category pairs) of p x , y , learn something about p y | x . ρ ( x ) = E [ y | x ] , or approximate p y | x itself. Note p x , y is unknown.
deep unsupervised learning x 2 representation of the input. contains a compact, latent After training, the hidden layer identity, this reduces to PCA. Here W is the parameter to learn. Minimize the reconstruction error Auto-encoder layer Reconstruction x 6 x 5 x 1 x 3 x 4 15 h 1 x 2 x 3 x 4 x 5 x 6 x 1 layer Input h 2 h 3 Hidden layer ∥ x − ˜ x ∥ 2 , where ˜ x = σ ( W ⊤ h ) ˜ ˜ h = σ ( Wx ) ˜ ˜ When the nonlinearity σ ( · ) is ˜ ˜
deep unsupervised learning Stacked Auto-encoder (deep models) 2 W Denoising Auto-encoder ∙ Train an auto-encoder by 16 Reconstructing noise-corrupted input. Minimize ∥ x − ˜ x ∥ 2 , where x = σ ( W ⊤ h ) , ˜ h = σ ( W ( x + ε )) ε could be white noise or domain specific noises. Layer-wise training: let h ( 0 ) = x , for l = 1 , . . . , L � � W ∗ = arg min � h ( l − 1 ) − σ ( W ⊤ σ ( Wh ( l − 1 ) )) � � � ∙ Let h ( l ) = σ ( W ∗ h ( l − 1 ) )
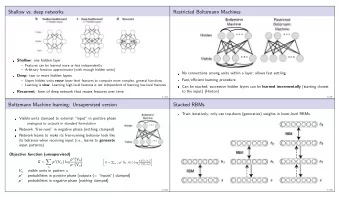
deep unsupervised learning Conditional probabilities are factorized out, and likelihood to estimator model parameters. Layer-wise (pre) training with maximal (log) n m easy to compute 17 Ristricted Boltzmann Machines Ristricted Boltzmann Machine h3 Ze − E ( x , h ) , P ( x , h ) = 1 E ( x , h ) = − a T x − b T h − x T Wh h2 h1 ∏ ∏ P ( x | h ) = P ( x i | h ) , P ( h | x ) = P ( h j | x ) i = 1 j = 1 x Deep Belief Network
deep unsupervised learning (Deep) Unsupervised Learning is ∙ Typically used to initialize supervised deep models. ∙ Unsupervised pre-training is no longer used in most of the cases nowadays when abundant supervised training data is available. ∙ Empirically not performing as good as supervised models, but considered very important because ∙ Unsupervised data is much cheaper to get than labeled data. ∙ Humans are not trained by looking at 1 million images with labels. ∙ Able to do probabilistic inference, sampling, etc. 18
deep supervised learning Deep Neural Networks (DNNs), a.k.a. Multi-Layer Perceptrons (MLPs) MLP with one hidden layer is a universal approximators for continuous functions. sigmoid, rectified linear unit, etc. 19 x ( l + 1 ) = σ ( W ( l ) x ( l ) + b ( l ) ) Typical nonlinearity σ ( · ) :
deep supervised learning Deep Neural Networks probability distribution over the output alphabet. approximate the posterior distribution over HMM states y given the observation x . ∙ Deeper models usually outperform shallow models with the same number of parameters. ∙ But we do not know why... ∙ Objective function is non-convex, non-linear, non-smooth; usually trained with stochastic gradient descent for a local optimal. Typical learning curves of SGD: 20 ∙ Softmax is typically used at the last layer to produce a ∙ e.g. In speech recognition, a MLP q θ ( y | x ) is trained to
deep supervised learning Recurrent Neural Networks (RNNs) image source: http://arxiv.org/abs/1412.5567 ∙ Hidden layers takes inputs from both lower layers and the same layer from the previous (or next) time step. ∙ Expanded over time: a (very) deep neural network with shared weights. ∙ Widely used in speech recognition and natural language processing to process sequence data. 21
deep supervised learning ∙ RNNs are very difficult to train. ∙ Gradients diminish or explode when back-propagate over time. ∙ Many variants proposed to improve (empirical) convergence property. ∙ Long-short Term Memory (LSTM]) 22
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries